A journey for search - From MySQL to ElasticSearch
Out Of Date Warning
This article was published on 14/09/2014, this means the content may be out of date or no longer relevant.
You should verify that the technical information in this article is still up to date before relying upon it for your own purposes.
Running several job-boards around Empfehlungsbund, having a good and fast search was always important for us. Started out with a basic MySQL LIKE search, we tested several alternatives along the way. Recently, we settled on ElasticSearch. Here, I want to recap what we learned during that time.
In comparison to finding the "most relevant" search results, for us, transparency of the algorithm was as important, as we had to explain to our (paying) customers, how they can influence the ranking. I want to lay down, how we developed our search algorithm over time and reason about the decisions made.
Table of Contents
MySQL LIKE – 2009-2014
 ITsax.de was launched before my arrival at pludoni GmbH in 2009. The initial search was implemented with straight MySQL
ITsax.de was launched before my arrival at pludoni GmbH in 2009. The initial search was implemented with straight MySQL LIKE %query% and a naïve scoring, which just boosted a found match by a fixed boost score (Title: 2.5, description: 1, tags: 1.5). Matches in all 3 parts of the job yielded 5 points max.
Later in 2010, I partially rewrote the algorithm, which scored matches of synonyms (searching for Java also scored J2EE etc.) with a lesser score and improved speed. Jobs with the same score were sorted randomly.
- Search index: 50-200 jobs
- Technologies: PHP and raw SQL (MySQL Isam LIKE)
Pro:
|
Cons:
|
Sphinx 2012-2013
- Search index: 500-1200
- Technologies: Ruby/Rails, Thinking Sphinx
As our job websites were growing, we started to develop a central administration platform, the Empfehlungsbund. Secondly, visitors can search through all of our jobs simultaneously. Using a simple SQL search was a too slow. Also, I'd like to try out other technologies, specifically made for this purpose.
The Ruby on Rails integration Thinking Sphinx gave us a good head start and developing something working was easy enough, in the beginning. But after a while, we were hitting some road bumps, as there some complexity we couldn't always grasp. Partial searching and synonyms were not always working as expected. Especially the requirement to rank synonym matches lower was difficult to achieve (AFAIR).
Pros
|
Cons
|
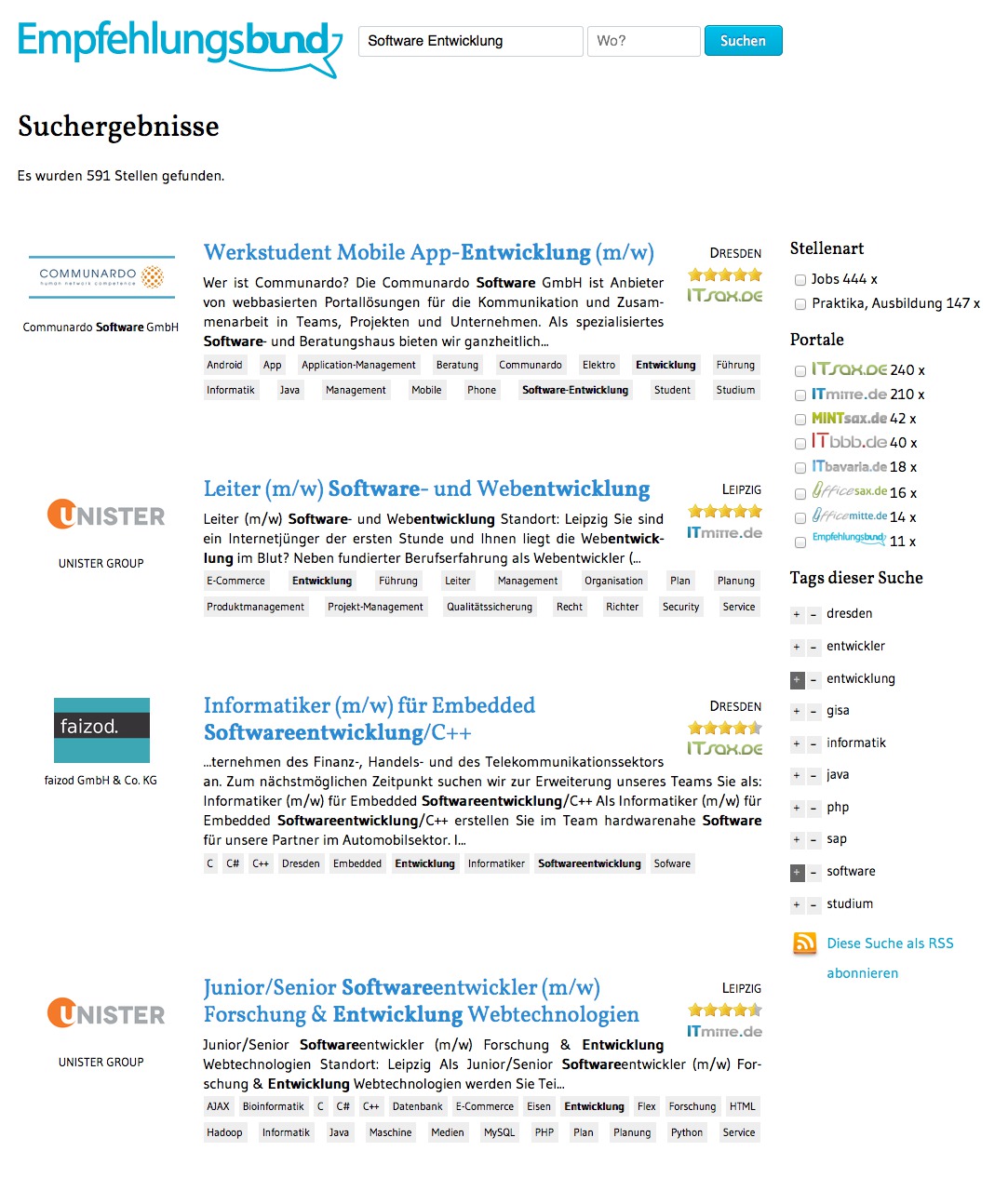
ElasticSearch v1 2013-2014
In 2013, Martin wrote his Master Thesis at our company. After his analysis, we decided to shoot for ElasticSearch, which wasn't 1.0 yet, but extremely promising. In the beginning, hacking the scoring was a bit of a hassle. Martin developed a custom ElasticSearch plugin, which dumped the default BM25 and TF-IDF scorings. We discarded those statistic scores after trying them for some time. We didn't saw too much benefit and explaining those metrics to our customers would be difficult.
- Search index: 700-1200 active jobs,
- Technologies: Ruby/Rails, Tire integration, ElasticSearch 0.90.x
Pros
|
Cons
|
ElasticSearch v2 2014*
In the middle of 2014, I started to attack that problem once again. Intrigued by the embedded scripting language Groovy, I started to play around and develop a search algorithm using the function_score query.
At the same time, our Ruby mapping library, (Re)tire was discontinued and the Ruby part needed a considerable rewrite using ElasticSearch-Ruby, too.
At the moment, we are very satisfied with the result quality, the execution time is a different kind of beast, though. In another blog post, I will describe our algorithm in detail.
In short: We "solved" the partial matching by indexing n-grams and count, how many n-grams of the query string are found in the document.
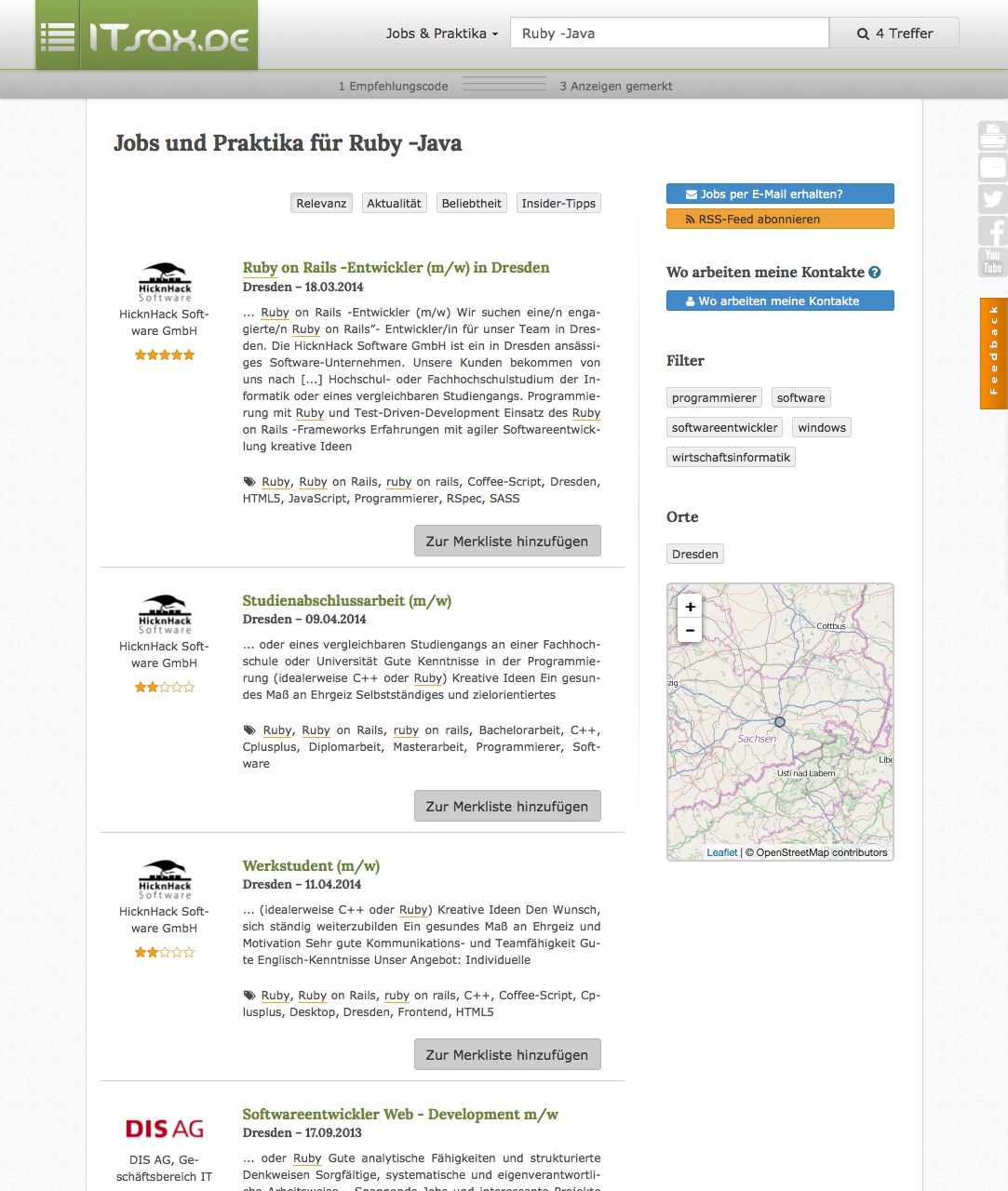
Pros
|
Cons
|
Conclusion
We used a very basic MySQL search for quite some time – Our PHP software and the MySQL search has been used until May 2014. We used our job board Empfehlungsbund as a playground for trying out different technologies and now settled for a satisfying solution.
Learning and understanding tools like ElasticSearch can take up quite some time. Not all projects need this kind of sophisticated search capabilities. Also, an additional process needs to be installed, configured and monitored; Development environments need to be set up as well. For some projects, just using the (limited) search caps of the database already in use might suffice, leads much quicker to results, and has almost no management overhead. For my side project Podfilter.de, I just use PostgreSQL's tsvector + Rails pgsearch gem, which can quickly search through thousands of podcasts descriptions in milliseconds.